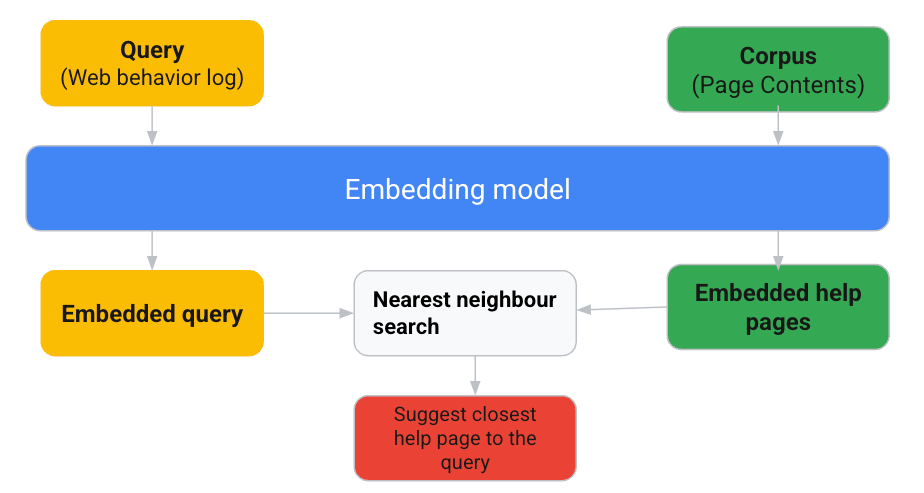
Vertex AI Embeddingsでユーザー体験を向上:ユーザーの意図を理解する
NewsPilot編集部
Cloud News Pilot
Google Cloudは、Vertex AI Model Gardenにおいて、TPUに最適化されたLLMサービングフレームワーク「Hex-LLM」を発表しました。これは、オープンソースモデル向けに、TPU上で高効率かつ低コストなLLMサービングソリューションを提供するものです。
Vertex AI Model Gardenは、効率的かつコスト最適化されたMLワークフローを提供するサービスであり、150を超えるファウンデーションモデルが利用可能です。今回のHex-LLMの追加は、LLMの運用コスト削減に大きく貢献するものであり、非常に興味深いと感じました。
近年、LLMの規模は飛躍的に拡大しており、それに伴い、その運用コストも増大しています。従来のGPUベースのサービングでは、コスト効率が課題となっていましたが、Hex-LLMは、Google CloudのTPUを活用することで、この課題を解決しようとしています。
記事では、Hex-LLMが、連続バッチ処理やページングされたアテンションなどの最新のLLMサービング技術と、XLA/TPU向けに調整された最適化を組み合わせていることが説明されています。また、GemmaやLlama 2、Mistralなど、幅広いLLMモデルをサポートしている点も魅力的です。
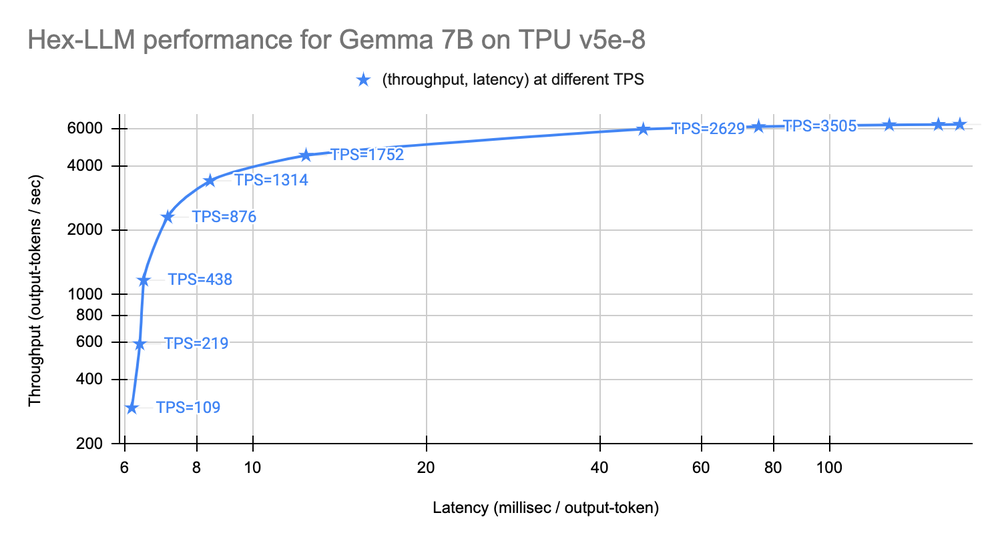
ベンチマークの結果を見る限り、Hex-LLMは、高いスループットと低いレイテンシを実現しており、パフォーマンス面でも期待できるものとなっています。特に、Llama 2 70Bのような大規模なモデルにおいても、優れたパフォーマンスを発揮している点は注目に値します。
Hex-LLMは、Vertex AI Model Gardenのプレイグラウンド、ノートブック、ワンクリックデプロイを通じて利用可能とのことなので、手軽に試すことができる点も魅力です。
今後、LLMの活用がますます進む中で、Hex-LLMのような、高効率かつ低コストなサービングソリューションの需要はますます高まっていくでしょう。Google Cloudが、今後もLLMサービング技術の進化をリードしていくことを期待しています。
参照元サイト:Hex-LLM: High-efficiency large language model serving on TPUs in Vertex AI Model Garden