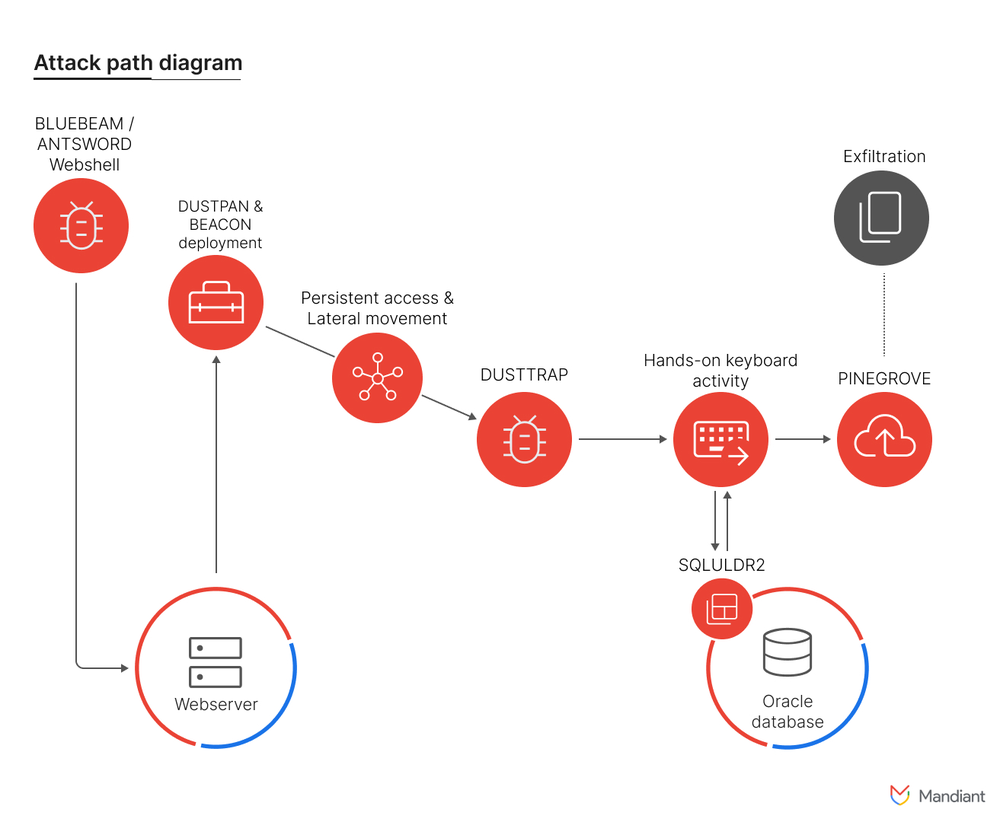
APT41、物流業界を標的に高度なマルウェア「DUSTTRAP」キャンペーンを展開
NewsPilot編集部
Cloud News Pilot

Google Cloudは、Cloud SQLのメタデータをDataplex Catalogに自動的にカタログ化する機能を発表しました。これにより、ユーザーはCloud SQLのデータ資産をより深く理解し、データ管理を効率化し、データドリブンな取り組みを加速させることができるようになります。
特に興味深い点は、データの発見と管理に苦労している企業にとって、この統合が大きな助けになるということです。データ量が増加するにつれて、必要なデータを必要な時に見つけることは困難になります。Dataplex Catalogは、Cloud SQLインスタンス、データベース、テーブル、ビューなどのメタデータを自動的に抽出・整理してくれるため、データの探索が容易になります。
例えば、ある企業が顧客データ分析用の新しいダッシュボードを作成するときに、必要なデータがどのCloud SQLインスタンスのどのデータベースに存在するのか、すぐに分からず、多くの時間を費やしてしまうことがあります。Dataplex Catalogを使えば、顧客データに関する情報を持っているデータベースを簡単に検索し、必要なデータにアクセスすることができます。
さらに、Dataplex Catalogは、データのガバナンス強化にも役立ちます。データの機密性やデータの所有者など、カスタムメタデータやビジネスコンテキストをデータエントリに添付することができます。この機能により、企業はデータのコンプライアンスを確保し、データガバナンスを強化することができます。
例えば、GDPRなどのデータプライバシー規制に準拠するためには、個人データの保存場所と使用方法を把握することが重要です。Dataplex Catalogを使えば、個人データが格納されているデータベースを特定し、データへのアクセスを制御することができます。
ただし、Dataplex Catalogはあくまでもメタデータ管理ツールであるため、データの品質や整合性については、別途担保する必要があります。データ品質の向上や整合性の確保には、データクレンジングツールやデータ品質管理ツールなどを活用する必要があります。
今回のCloud SQLとDataplex Catalogの統合は、データ管理の複雑さを軽減し、データからの価値創出を加速させるための重要な一歩と言えるでしょう。
参照元サイト:Unlocking the power of your Cloud SQL data with Dataplex Catalog