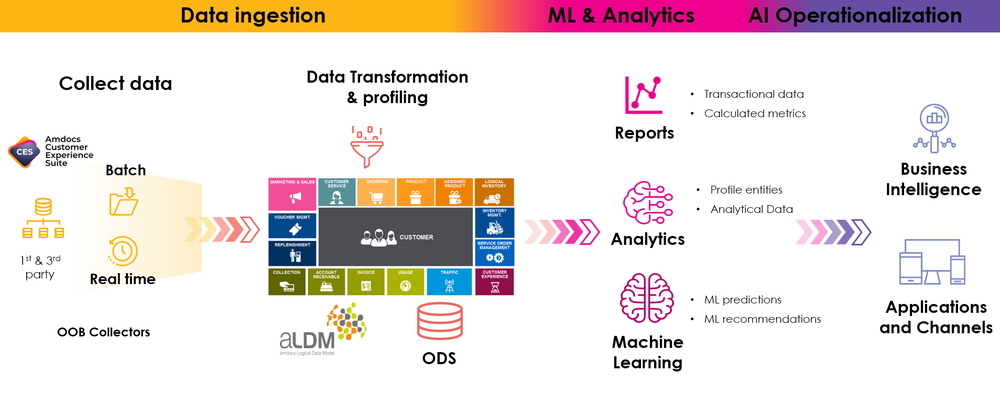
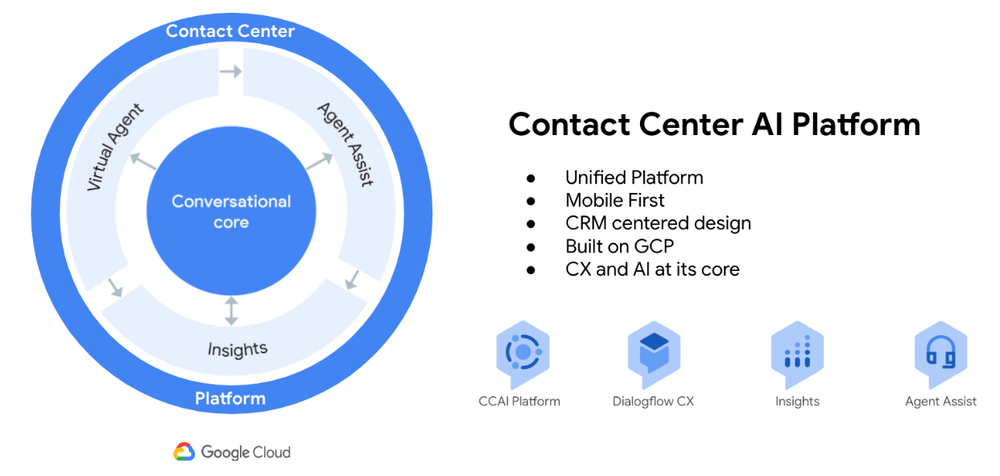
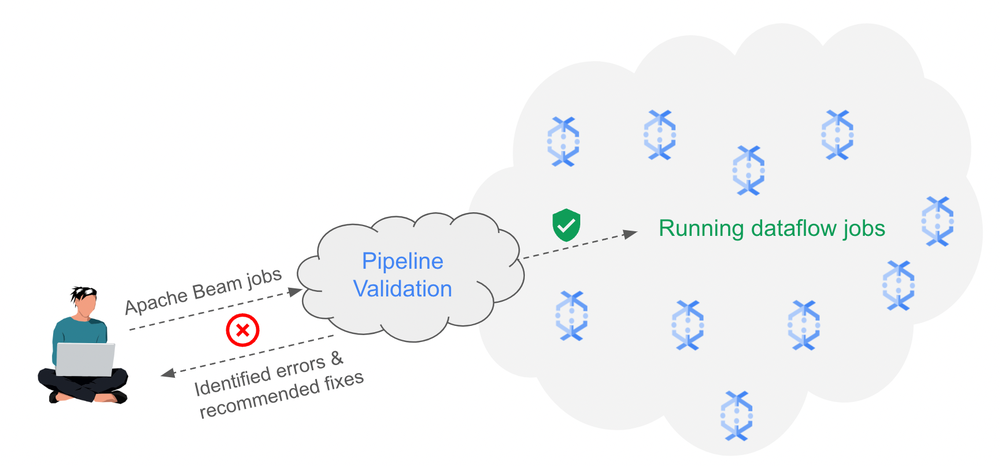
Amdocs、Google Cloudとの連携で通信業界の顧客体験を革新
NewsPilot編集部
Cloud News Pilot
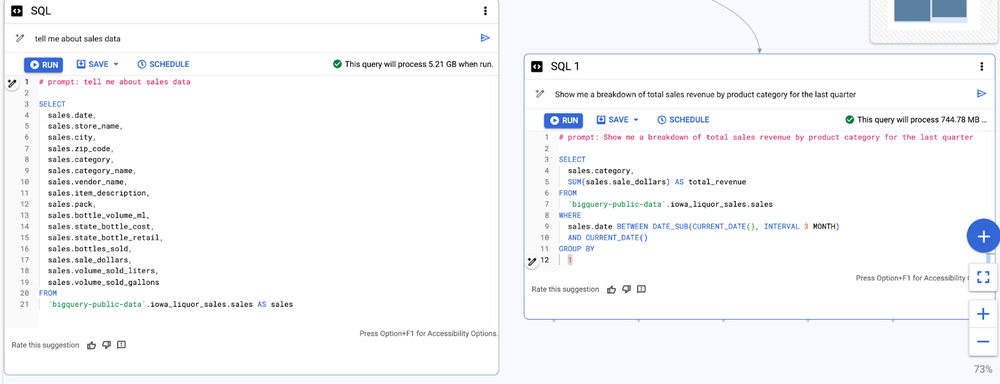
Google Cloudは、BigQueryデータキャンバスで自然言語からSQLを生成する際の精度を高めるためのプロンプト作成に関する5つのヒントを紹介しました。
近年の生成AIの進化により、自然言語を使ってデータ分析を行うことが一般的になりつつあります。BigQueryのデータキャンバスもその一つで、Geminiという基盤モデルを用いることで、自然言語からSQLやチャートを生成できます。しかし、生成AIは万能ではなく、適切な指示を与えないと期待通りの結果を得られないことがあります。
記事で紹介されている5つのヒントは、まさにこの問題を解決するためのものです。曖昧な表現を避け、明確で具体的な指示を与えること、関連情報を提供すること、一度に一つの質問に絞ること、重要な用語を強調すること、操作の順序を明確にすること、これらのヒントを実践することで、より正確で思い通りの結果を得られる可能性が高まります。
特に興味深いと感じたのは、「操作の順序を明確にすること」という点です。人間であれば文脈から判断できるような場合でも、AIは指示された通りの順序で処理を行うため、意図しない結果になることがあります。記事では、指示の順序を変えただけで、生成されるSQLがどのように変化するのか、具体的な例を挙げて解説しています。
BigQueryデータキャンバスに限らず、生成AIを活用する上で、どのように指示を与えればよいかは常に課題となります。今回の記事は、BigQueryデータキャンバスユーザーだけでなく、生成AIを活用するすべての人にとって有益な情報と言えるでしょう。
しかし、記事で紹介されているヒントはあくまでも一般的なものであり、すべてのケースに当てはまるわけではありません。重要なのは、試行錯誤を繰り返しながら、自身の利用環境や目的に最適なプロンプトを見つけ出すことです。Google Cloudは、GitHub上でサンプルのプロンプトを公開しているので、それらを参考にしながら、自分自身のプロンプトを改善していくことをおすすめします。
参照元サイト:Prompting best practices for BigQuery data canvas